Device Detection
8/2011
Device detection is very straight forward. A browser hits your web server: figure out what type of device it is and then respond with content tailored to its capabilities. If you do this well your users will have a good experience.
There are a few ways to accomplish device detection. One way is to create a set of regular expressions which will look for certain patterns in a browser's user agent string and match them up against particular devices. This is not a bad solution. This can be done at the front of the web stack. However, it requires a large number of complex expressions if you want to support all the different devices floating around today. Another approach would be to leverage a device database like WURFL and use it for device classification. This solution has many merits. It's precise, so you are almost guaranteed that no devices will fall through the cracks. But this comes at a price. The WURFL APIs have measurable overhead and are written in high level languages. Detection would have to be done at the back-end of the web stack which will be costly. The perfect solution here would be combining the completeness of WURFL with the speed and location of regular expressions.
Luckily, this solution is within reach. First, the WURFL data needs to be paired down into a basic set of pattern matching rules. Then, the rule set needs to be applied to a browser's user agent string in real time. Speed and efficiency are essential here. To satisfy the speed part, I picked C as the implementation language. This is a good choice since many high performance web systems are written in C, so integration will be easy. As for efficiency, I paid careful attention to data modeling and memory access. I implemented the rule set inside of a fast search algorithm which then sits on top of a pointer compression system. This delivered unmatched performance. The final result is a device detection API which can quickly and accurately classify a device with little to no measurable CPU or memory overhead.
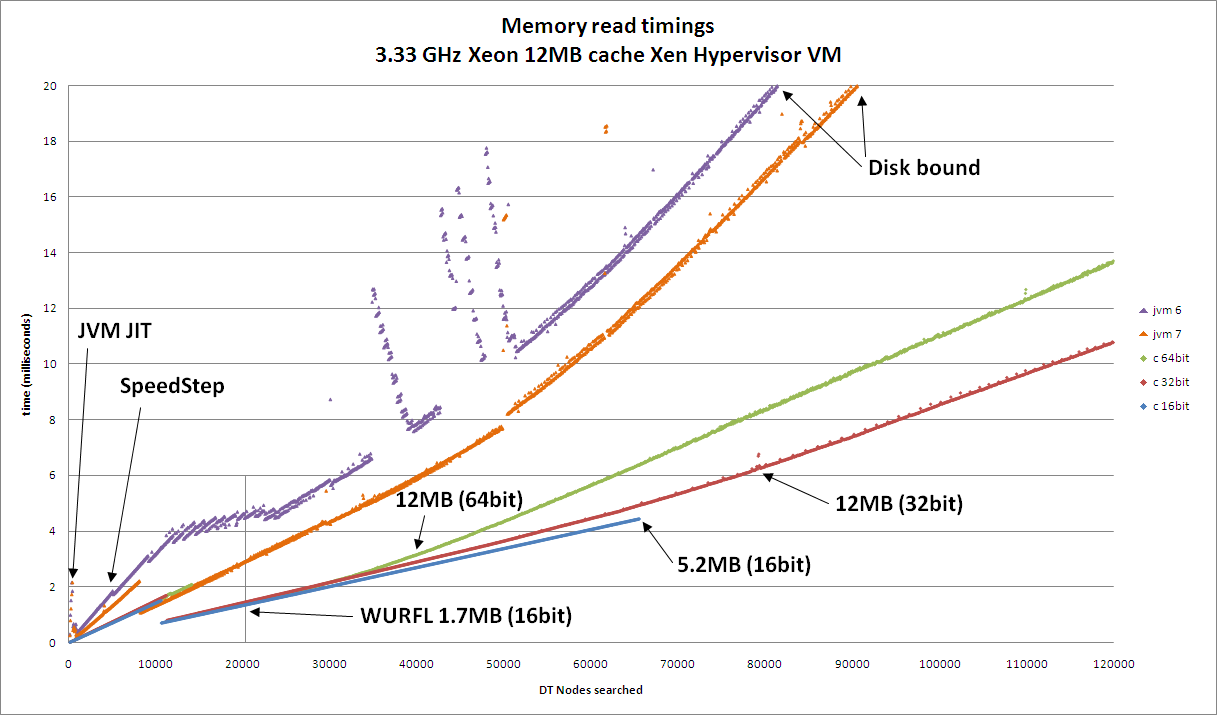
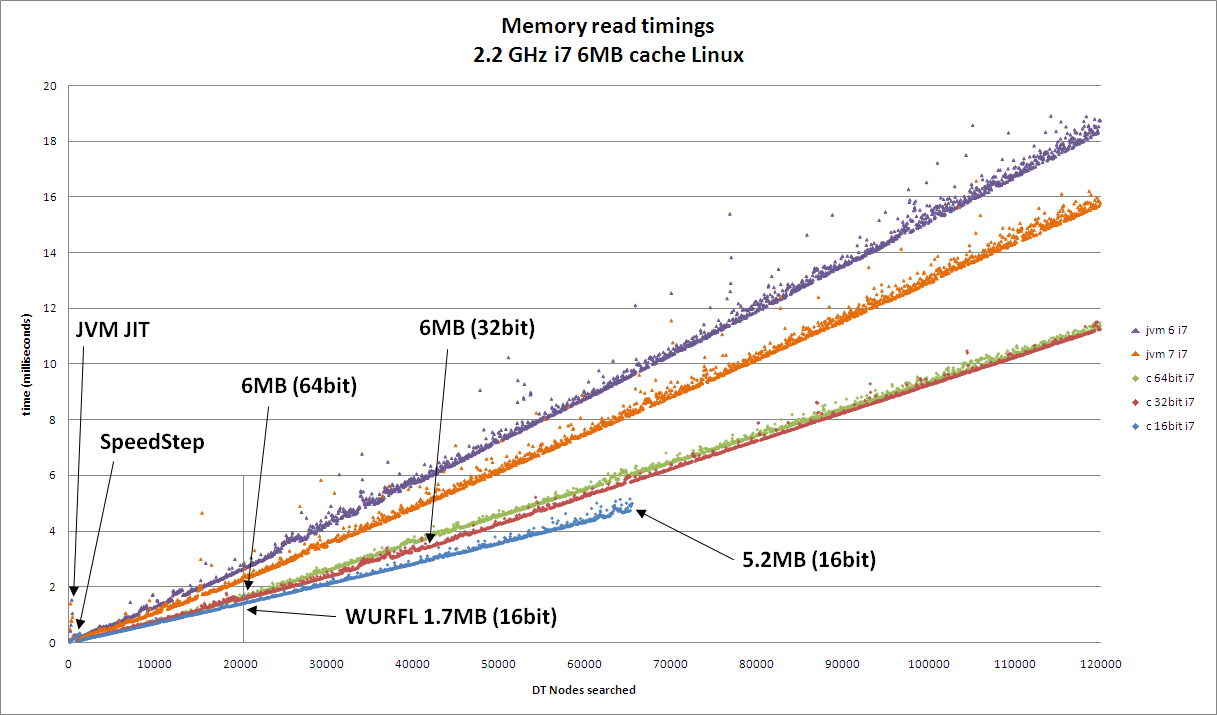
Some interesting performance metrics can be seen on the corresponding graphs. On the first graph, you can clearly see the costs (or benefits) associated with hitting CPU cache, system memory, and virtual memory. On the second graph, we see a totally different set of performance metrics. On this system, main memory reads are almost indistinguishable from CPU cache reads. Also, Java performance on this system is more in line with C performance. Overall, it is clear that performance is highly dependent on memory performance. On both systems, this implementation can easily achieve millions of real time classifications a second per core. This highlights an important point, careful attention to and understanding of language, algorithms, memory, and system tuning are instrumental in achieving high levels of performance from your software.
Source code v1.4
Source code v2.0+
Mirror
Home